在網(wǎng)絡(luò)編程的世界里,性能是開發(fā)者永恒的追求。在通往高性能網(wǎng)絡(luò)應(yīng)用的道路上,有一塊巨大而常見的“絆腳石”——同步阻塞網(wǎng)絡(luò)I/O。它以其直觀簡單的模型,吸引著無數(shù)初學(xué)者,卻也因其固有的缺陷,成為系統(tǒng)吞吐量和并發(fā)能力提升的主要瓶頸。本文將通過圖解的方式,深入剖析同步阻塞網(wǎng)絡(luò)I/O的工作原理、性能瓶頸及其在高并發(fā)場景下的困境。
一、 什么是同步阻塞網(wǎng)絡(luò)I/O?
同步阻塞I/O是最經(jīng)典、最直觀的網(wǎng)絡(luò)編程模型。其核心特點是:進(jìn)程(或線程)在進(jìn)行I/O操作(如read, accept, connect)時,必須等待該操作徹底完成(數(shù)據(jù)就緒且從內(nèi)核空間拷貝到用戶空間)后才能繼續(xù)執(zhí)行后續(xù)代碼。在此期間,調(diào)用者會被操作系統(tǒng)掛起,進(jìn)入“阻塞”狀態(tài),無法執(zhí)行任何其他任務(wù)。
我們可以用一個簡單的“服務(wù)員-顧客”餐廳模型來比喻:
- 同步:服務(wù)員(應(yīng)用程序線程)必須親自完成從點單(發(fā)起請求)到上菜(獲得數(shù)據(jù))的整個流程,不能中途離開去服務(wù)其他桌。
- 阻塞:如果廚房(內(nèi)核/網(wǎng)絡(luò))做菜很慢,服務(wù)員就必須在出菜口一直站著等,直到菜做好端走。這段時間他什么都干不了。
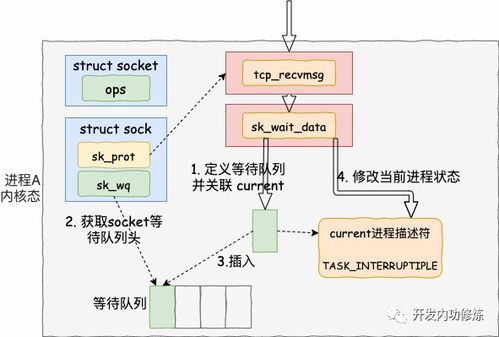
二、 工作原理圖解:以Socket read()為例
讓我們跟隨一次典型的Socket讀取操作,看看線程是如何被“卡住”的。
[用戶空間] [內(nèi)核空間] [網(wǎng)絡(luò)/磁盤]
| | |
| 調(diào)用 read(socket) | |
|------------------>| |
| | 數(shù)據(jù)未就緒,線程阻塞 |
| 線程被掛起 |<---等待數(shù)據(jù)包------|
| (阻塞中) | |
| | 數(shù)據(jù)到達(dá),拷貝至內(nèi)核緩沖區(qū) |
| |<===================|
| | 數(shù)據(jù)從內(nèi)核緩沖區(qū)拷貝到用戶緩沖區(qū) |
| 線程被喚醒 |------------------>|
|<------------------| |
| read()返回,繼續(xù)執(zhí)行 | |關(guān)鍵的兩階段等待:
1. 等待數(shù)據(jù)就緒:數(shù)據(jù)包還在網(wǎng)絡(luò)上“飛”,或者對端還未發(fā)送。此時,內(nèi)核讓線程休眠,直到數(shù)據(jù)到達(dá)網(wǎng)卡并被拷貝到內(nèi)核的接收緩沖區(qū)。
2. 等待數(shù)據(jù)拷貝:數(shù)據(jù)到達(dá)內(nèi)核緩沖區(qū)后,內(nèi)核需要將其從內(nèi)核空間拷貝到用戶空間(即read函數(shù)指定的應(yīng)用層緩沖區(qū))。完成拷貝后,read調(diào)用才返回成功。
在整個過程中,調(diào)用線程在“等待就緒”和“等待拷貝”這兩個階段都是完全停滯的。
三、 為何成為高性能的“絆腳石”?
同步阻塞模型的簡單性是以犧牲資源利用率和并發(fā)能力為代價的。
1. 線程資源浪費嚴(yán)重(圖解:線程池的窘境)
在高并發(fā)服務(wù)器中,通常采用“一個連接一個線程”的模式。
[客戶端1] ---> [線程1:阻塞在read()上]
[客戶端2] ---> [線程2:阻塞在accept()上]
[客戶端3] ---> [線程3:阻塞在read()上]
[客戶端4] ---> [線程4:正在處理...]
[客戶端...] [線程N(yùn):大部分時間在沉睡]
\ /
[線程池]- 問題:每個連接都需要一個獨立的線程服務(wù)。而線程是操作系統(tǒng)寶貴的資源,創(chuàng)建、銷毀、調(diào)度都有開銷。成千上萬的連接意味著成千上萬的線程,上下文切換將消耗大量CPU時間。
- 更糟的是:這些線程中的絕大部分時間都花在
read、write的等待上(即上圖的“阻塞中”狀態(tài)),CPU處于閑置狀態(tài)。資源(線程內(nèi)存、調(diào)度開銷)被大量占用,卻未產(chǎn)生實際計算價值。
2. 并發(fā)能力受限于線程數(shù)
系統(tǒng)的最大并發(fā)連接數(shù)理論上等于線程池的最大線程數(shù)。而一個進(jìn)程能創(chuàng)建的線程數(shù)是有限的(受限于內(nèi)存、內(nèi)核參數(shù)等)。通常,當(dāng)并發(fā)連接數(shù)超過數(shù)千時,這種模型就會變得極其低效甚至崩潰。
3. 慢客戶端導(dǎo)致的級聯(lián)阻塞
如果一個客戶端網(wǎng)絡(luò)很慢,讀取它發(fā)送的一個數(shù)據(jù)包需要5秒,那么服務(wù)它的線程就會被堵住5秒。這期間,該線程無法處理其他任何請求。如果這樣的慢客戶端多了,線程池中的線程會迅速被“凍住”,即使服務(wù)器CPU空閑,也無法響應(yīng)新來的快速客戶端,導(dǎo)致服務(wù)整體癱瘓。
四、 與高性能模型的對比
理解阻塞之痛,才能明白非阻塞I/O、I/O多路復(fù)用(如select/poll/epoll)、異步I/O等高性能模型的價值。它們的核心思路是一致的:讓一個線程能夠管理多個連接,只在連接真正有I/O事件可處理(數(shù)據(jù)可讀、可寫)時,才進(jìn)行實際操作,避免無謂的等待。
以Linux的epoll為例的對比示意圖:
`
同步阻塞模型 (1:1)
線程A ---> 連接1 (阻塞)
線程B ---> 連接2 (阻塞)
線程C ---> 連接3 (阻塞)
... 一萬個連接需要一萬個線程。
I/O多路復(fù)用模型 (1:N)
|--- 連接1 (有數(shù)據(jù),處理)
線程A ---> |--- 連接2 (無事件,跳過)
| |--- 連接3 (有數(shù)據(jù),處理)
(epoll) |--- ... 一萬個連接
|--- 連接10000 (無事件,跳過)`
一個工作線程通過epoll<em>wait可以同時監(jiān)聽上萬個連接。當(dāng)其中某些連接有事件發(fā)生時,epoll</em>wait返回,線程只去處理這些“活躍”的連接,處理完繼續(xù)監(jiān)聽。線程資源被高效復(fù)用。
五、 與啟示
同步阻塞網(wǎng)絡(luò)I/O是學(xué)習(xí)網(wǎng)絡(luò)編程的重要起點,它清晰地揭示了I/O操作的本質(zhì)。但在生產(chǎn)環(huán)境,尤其是需要高并發(fā)、高性能的服務(wù)器場景(如Web服務(wù)器、游戲網(wǎng)關(guān)、即時通訊服務(wù)等)中,它已成為必須跨越的“絆腳石”。
- 適用場景:客戶端程序、并發(fā)要求極低(如內(nèi)部管理工具)、或追求極致簡單性的場景。
- 規(guī)避策略:邁向高性能,必須掌握非阻塞I/O與I/O多路復(fù)用技術(shù)(
select/poll/epoll/kqueue),或直接使用基于這些機(jī)制的高級框架(如Netty、libevent)。對于磁盤I/O,則可考慮使用異步I/O(AIO)。
理解這塊“絆腳石”,不僅是為了避開它,更是為了深刻理解操作系統(tǒng)如何進(jìn)行I/O調(diào)度、應(yīng)用程序如何與內(nèi)核協(xié)作,從而為構(gòu)建真正高性能、高可用的網(wǎng)絡(luò)服務(wù)打下堅實基礎(chǔ)。